

1. Introduction
Retrieval-Augmented Generation (RAG) combines large language models (LLMs) with external knowledge. Instead of relying solely on an LLM's internal (parameterized) memory, a RAG system retrieves relevant evidence from specialized datasets, knowledge bases, or even multi-modal content, then feeds that context to the LLM. As a result, the system:
- Answers more accurately and reduces hallucinations (because it references external knowledge).
- Remains up-to-date (by re-indexing external data without needing to retrain the LLM).
- Offers interpretability (by revealing which external sources contributed to the final answer).
In modern AI applications, RAG sits at the intersection of embeddings, vector databases, prompt engineering, agentic workflows, and guardrails.
2. Embeddings: Fundamentals and Practical Usage
2.1 Why Embeddings Are Central
- Semantic Similarity: Cosine similarity between query and document vectors locates conceptually close chunks.
- Scalability: Efficient approximate nearest neighbor (HNSW / ScaNN) search can quickly find relevant chunks among thousands or millions. Even billions of vectors can be retrieved in less than 100 milliseconds (p95).
- Modularity: You can re-embed or update external data without retraining your LLM.
2.2 Chunking Text
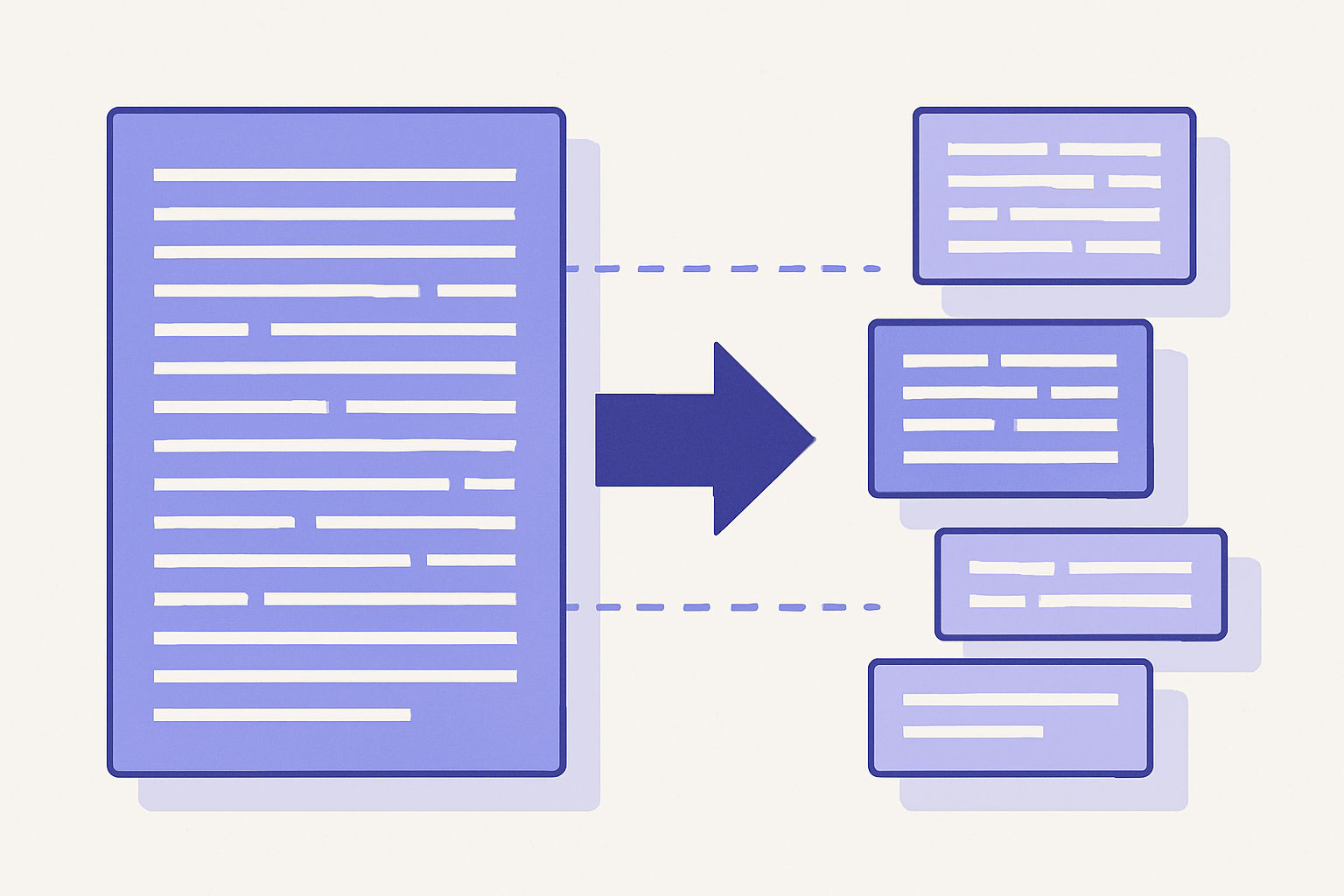
Large documents - like books, Wikipedia articles, or phone call transcripts - must be split into smaller chunks before embedding. Why chunk?
- Precision: A single representation for an entire 5,000-word article can be diluted. Smaller chunks preserve specificity.
- Context Window: The LLM can only process a certain amount of context. By retrieving multiple small chunks, we feed the model more targeted relevant text.
Examples:
- Books: Break each chapter into ~ 10-20 % of the model's context window (e.g., 1k tokens for a 8k window, 2-4k for a 32-128k window).
- Wikipedia: Split articles by headings to get the most knowledge in one chunk, so your system can retrieve the best paragraph for a given question.
- Phone Call Transcripts: Segment by time (e.g. 1-minute blocks) and as much as possible by speaker turns.
2.3 Popular Embedding Solutions
- OpenAI's text-embedding-3: High-performance, small 512 or large 1536 dimensional vectors, easy integration if you're already using OpenAI's API.
- Cohere's Embed 4: State-of-the-art accuracy, multi modality (text, images, graphs, diagrams, code), high context window (128k tokens, around 200 pages) and works across 100+ languages.
- e5-large-v2: Open-weights, one of the better open model for semantic search.
- ImageBind from Meta: Cross-modal embeddings for images, audio, text and more.
In practice, you may use multiple embeddings based on the type of data and store them in separate vector databases. Then for each search you can search in each vector database. Or you can use multi-modal embedding models and store in one db. For images for example you can use OpenCLIP or OpenAI's Vision Model - (both gpt-4o and gpt-4.1 support it) to first convert the image to text and then embed the text.
3. High-Level Workflow
RAG always revolves around these two stages:
- Retrieval: Embedding-based search of an external corpus.
- Augmented Generation: The LLM sees retrieved snippets + the user query.
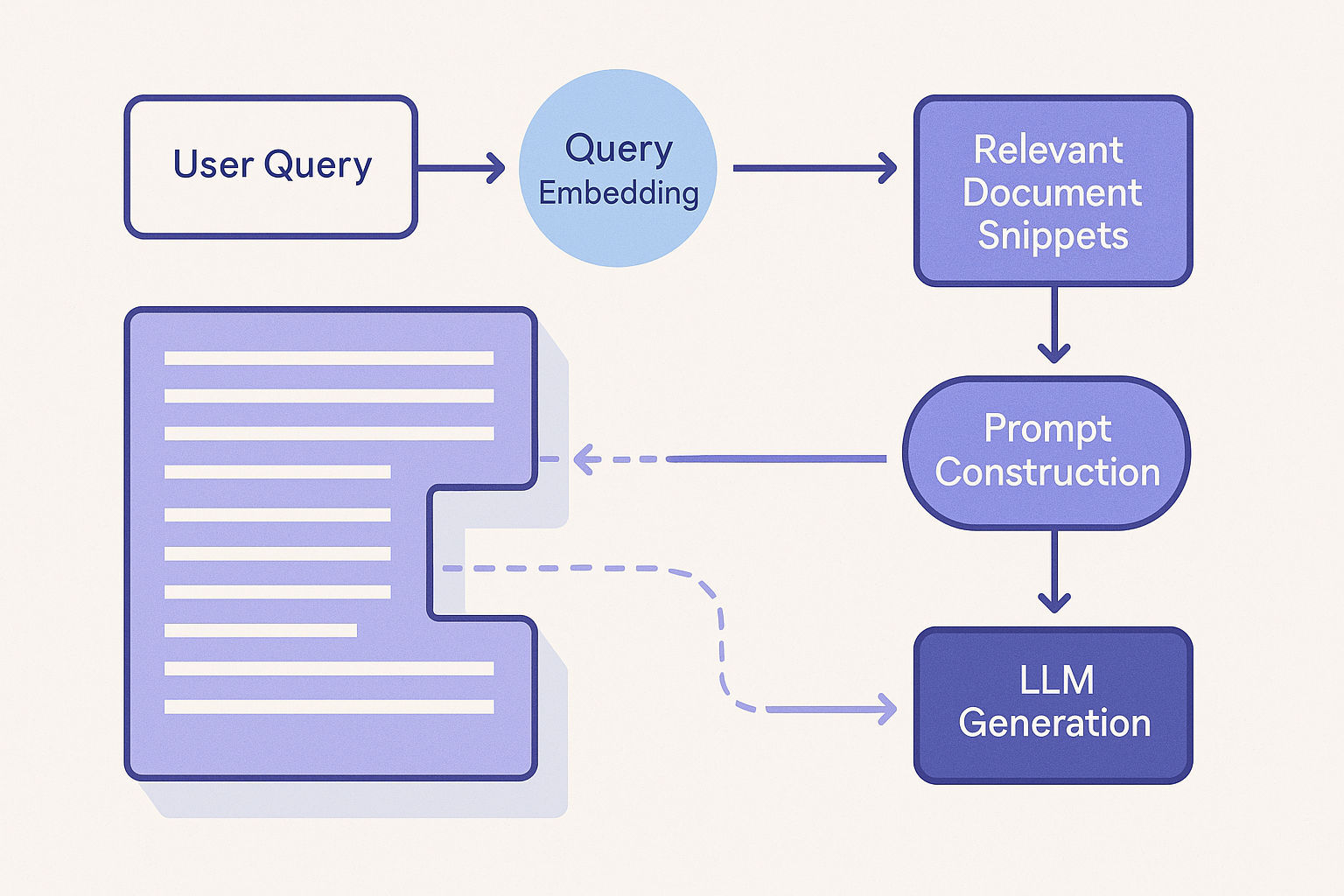
Why is it so effective? Because the LLM's internal knowledge is supplemented with up-to-date or domain-specific text, reducing hallucinations and providing clearer insights.
4. The Retrieval Step
4.1 Embedding the Query
When a user queries the system - e.g. "How do I optimize an index?" - the query is turned into an embedding (using the same model used to embed your chunks). Then the system runs an ANN similarity search in the vector database.
4.2 Indexing, ANN, and Efficiency
You typically store chunk embeddings in a specialized database (Faiss, Annoy, Qdrant, Pinecone, Weaviate, etc.). Key ANN algorithms:
- HNSW: Graph-based approach with multi-layer neighbor links, offering O(log N) search, usually used for less than 2 billion vectors.
- ScaNN: Google's 'Scalable Nearest Neighbors' search algorithm, optimized for high QPS.
- DiskANN: Microsoft's approximate nearest neighbor search algorithm optimized to be cost-effective for very large datasets.
- LSH: Hash-based method that buckets vectors with similar angles, usually not used in production because of high memory and low recall.
4.3 Balancing k
Selecting how many chunks to retrieve (k) is crucial. Too few might miss needed context, while too many could overwhelm the LLM.
A common formula is to retrieve around 80% of the optimal LLM's context window. So, the formula is:
k = floor((optimal_context_tokens / avg_chunk_tokens) * 0.8)
For example, if the optimal context window is 128k tokens and the average chunk size is 5k tokens, then k = floor((128000 / 5000) * 0.8) = 20 chunks to retrieve.
5. Augmented Generation
Once we have the top-k chunks:
- Format them in the prompt, often with clear delimiters like "----- snippet 1 ----".
- System instructions might say "Use only the following context to answer. If unknown, say 'not enough info.'".
- Send the combined prompt to the LLM.
5.1 Prompt Design Tips
- Set roles: "You are a domain specialist in X."
- Chain-of-thought: "Show your reasoning step by step."
- Citation style: "When referencing a snippet, mention snippet #."
5.2 Chain-of-Thought
Prompt the LLM to extract relevant snippets first from the retrieved chunks. You can use the returned snippets to later build the answer and ask the model to think step by step. You should only return the snippets if they are relevant to the question, sometimes the approximate nearest neighbors could be irrelevant, so it's best to check them first.
5.3 Actual Generation
The LLM merges the extracted snippets with its prior knowledge. If the snippet is relevant, the final output will be anchored in the provided context, drastically reducing hallucinations.
6. Advanced RAG Architectures
RAG can be taken further. Let's highlight some expansions:
6.1 Iterative & Adaptive Retrieval
Sometimes a single retrieval call is insufficient – multi-hop queries or extremely complex questions may require breaking queries into sub-queries and performing multiple retrieval steps.
6.2 Caching and Efficiency
To optimize performance with repeated queries, RAG systems employ several caching strategies:
- Query embedding cache: Stores previously computed query embeddings to skip duplicate encoding operations when the same or similar questions are asked.
- KV-cache reuse: Maintains partial LLM computation states (key-value pairs) for frequently asked questions, allowing the model to resume generation without recomputing from scratch.
- Hot-document sharding: Keeps frequently accessed document embeddings and chunks pinned in RAM for faster retrieval, dramatically reducing latency compared to disk-based lookups.
7. Domain-Specific Chatbots
With RAG, building specialized chatbots is straightforward. Suppose you have company product manuals, legal documents, or medical guidelines.
7.1 Building the Knowledge Base
- Gather relevant documents (PDFs, wikis, logs).
- Split them into chunks (~10-20% of the LLM's context window).
- Embed each chunk and store them in a vector database (e.g. Faiss, Annoy, pgvector, Qdrant, Pinecone, Weaviate, etc.).
7.2 Query Flow
Example: A user asks, "What are the key features of the Product?" The retriever finds relevant manual pages, and the prompt merges the user query with the top-3 chunks.
7.3 Example Code With LangChain
from langchain.document_loaders import WebBaseLoaderfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_community.vectorstores import Chromafrom langchain_openai import OpenAIEmbeddingsfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthrough, RunnableSequencefrom openai import AsyncOpenAIloader = WebBaseLoader("https://example.com/product-manual.html")docs = loader.load()vectorstore = Chroma.from_documents(docs,embedding=OpenAIEmbeddings(model="text-embedding-3-large"))retriever = vectorstore.as_retriever(search_type="mmr", k=6)prompt = ChatPromptTemplate.from_messages([("system", "Use only the context. Cite doc ids."),("user", "{question}")])chain = RunnableSequence(RunnablePassthrough.assign(context=retriever),prompt,AsyncOpenAI(model="gpt-4.1-mini", response_format="json"))print(chain.invoke({"question": "What are the key features of the Product?"}))
7.4 Extended Use Cases
Extended examples include:
- Medical chatbots: Provide up-to-date clinical guidelines for doctors.
- Legal Q&A: Cite exact paragraphs from legislation.
- Call Center Summaries: Quickly reference previous transcripts for relevant background.
8. Agentic RAG With Function Calling
While classical RAG follows a simple "retrieve, then generate" pattern, a new emerging trend is agentic RAG, where the LLM itself becomes an active participant. Through function calling capabilities, the LLM can dynamically decide if and when it needs more data, choose appropriate data sources, and even perform iterative checks. Acting as an agent, it can make multiple retrieval calls or skip them entirely if the information at hand is sufficient.
8.1 Fundamentals
An agentic RAG system can be described as:
- LLM Agent: An agent that can "reason" about next steps, maintain short-term memory, call external tools (like retrieval APIs, SQL databases, vector embeddings, image search, web search, etc), parse returned data, and continue its thought process.
- Agentic RAG: An agentic RAG using the LLM as an agent can make multiple retrieval calls, or skip retrieval if it’s not needed.
8.2 OpenAI Function Calling Example
import openaiimport jsonopenai.api_key = "YOUR_OPENAI_KEY"def get_chunks_from_db(query_str: str):"""Mocked function that returns relevant chunks for the query."""# In a real implementation, this would query a vector DB and return actual chunks# Example chunks for a product database query:mock_data = {"index": ["To optimize database indices, create them on frequently queried columns. For product tables, common index columns include product_id, category, and price range.","Composite indices combining multiple columns (e.g., category + price) can improve query performance for filtered product searches."],"product": ["Product XYZ features include: 1) Real-time inventory tracking 2) Automated reordering 3) Custom attribute support","Product pricing is calculated based on base cost, markup percentage, and current market conditions."]}return mock_data.get(query_str.lower(), [f"No specific data found for {query_str}"])tools_schema = [{"type": "function","function": {"name": "get_chunks_from_db","description": "Retrieves relevant text from a vector store by query.","parameters": {"type": "object","properties": {"query_str": {"type": "string"}},"required": ["query_str"]}}}]fn_map = {"get_chunks_from_db": get_chunks_from_db}def agentic_flow(user_query):response = openai.ChatCompletion.create(model="gpt-4.1-mini",messages=[{"role": "user", "content": user_query}],functions=tools_schema)msg = response["choices"][0]["message"]# If model calls the function, parse and invokeif "tool_calls" in msg and msg["tool_calls"]:for call in msg["tool_calls"]:tool_name = call["function"]["name"]args = json.loads(call["function"]["arguments"])# Execute the Python functionretrieved = fn_map[tool_name](**args)# Now pass the retrieved text backsecond_response = openai.ChatCompletion.create(model="gpt-4.1-mini",messages=[{"role": "user", "content": user_query},{"role": "tool", "content": json.dumps(retrieved)}])return second_response["choices"][0]["message"]["content"]else:# If no function call is madereturn msg["content"]answer = agentic_flow("How do I optimize an index for my product DB?")print("Agentic RAG answer:", answer)
Frameworks like CrewAI, LangGraph, or HoneyHive orchestrate larger agent graphs
8.3 Pros and Cons
Pros:
- The model decides whether retrieval is needed.
- Fewer manual "band-aid" heuristics.
- Potentially better for multi-domain or multi-tool usage.
Cons:
- Additional overhead: each function call is an extra round-trip.
- The model might misuse or skip tools if not carefully prompted.
- Potential higher latency if the agent calls multiple tools in series.
Still, agentic RAG offers a self-directed synergy between LLM reasoning and retrieval, which can be transformative for advanced multi-hop tasks.
9. Conclusion
We have traversed the entire RAG pipeline, from fundamentals and embeddings to advanced caching strategies, domain-specific chatbots, and agentic function-calling.
As large-scale systems continue to adopt Retrieval Augmented Generation, these combined techniques promise more adaptive, accurate, and domain-savvy AI solutions. By following these best practices, you can confidently deploy advanced RAG applications that remain fresh, relevant, and well-aligned with user needs.